Gave feedback: Fanny Chevalier, Petra Isenberg, Christian Cherek, Hendrik Heuer, Michael McGuffin, Krishna Subramanian, Philipp Wacker, Michael Correll, Jake Hofman, Lewis Chuang, Christian P. Janssen, Jeff Huang, Julie Schiller, Sayamindu Dasgupta, Benjamin Johansen, Gijs Huisman, Florian Echtler, Kai Lukoff, Jennifer Lee Carlson, Nediyana Daskalova, Jennifer J. McGrath, Emanuel Zgraggen
Endorsed: (Pending)
So far, this document covers the effect sizes of the difference between means. There are other types of effect sizes such as correlation as well. If you are interested to contribute this part, get in touch!
Broadly speaking, an effect size is “anything that might be of interest” (Cumming 2013) ; it is some quantity that captures the magnitude of the effect studied.
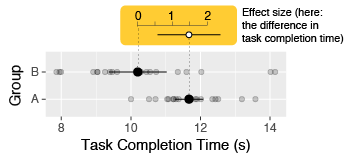
In HCI, common examples of effect size include the mean difference (e.g., in seconds) in task completion times between two techniques (e.g., using a mouse vs. keyboard), or the mean difference in error rates (e.g., in percent). These are called simple effect sizes (or unstandardized effect sizes).
More complex measures of effect size exist called standardized effect sizes (see What is a standardized effect size?). Although the term effect size is often used to refer to standardized effect sizes only, using the term in a broader sense can avoid unnecessary confusion (Cumming 2013; Wilkinson 1999a) . In this document, “effect size” refers to both simple and standardized effect sizes.
In quantitative experiments, effect sizes are among the most elementary and essential summary statistics that can be reported. Identifying the effect size(s) of interest also allows the researcher to turn a vague research question into a precise, quantitative question (Cumming 2014) . For example, if a researcher is interested in showing that their technique is faster than a baseline technique, an appropriate choice of effect size is the mean difference in completion times. The observed effect size will indicate not only the likely direction of the effect (e.g., whether the technique is faster or slower), but also whether the effect is large enough to care about.
For the sake of transparency, effect sizes should always be reported in quantitative research, unless there are good reasons not to do so. According to the American Psychological Association:
For the reader to appreciate the magnitude or importance of a study’s findings, it is almost always necessary to include some measure of effect size in the Results section. (American Psychological Association 2001)
Sometimes, effect sizes can be hard to compute or to interpret. When this is the case, and if the main focus of the study is on the direction (rather than magnitude) of the effect, reporting the results of statistical significance tests without reporting effect sizes (see the inferential statistics FAQ) may be an acceptable option.
The first choice is on whether to report simple effect sizes or standardized effect sizes. For this question, see Should simple effect sizes or standardized effect sizes be reported?
It is rarely sufficient to report an effect size as a single quantity. This is because a single quantity like a difference in means or a Cohen’s d is typically only a point estimate, i.e., it is merely a best guess of the true effect size. It is crucial to also assess and report the statistical uncertainty about this point estimate.
For more on assessing and reporting statistical uncertainty, see the inferential statistics FAQ.
Ideally, an effect size report should include:
This information can be reported either numerically or graphically. Both formats are acceptable, although plots tend to be easier to comprehend than numbers when more than one effect size needs to be conveyed (Loftus 1993; Kastellec and Leoni 2007) . Unless precise numerical values are important, it is sufficient (and often preferable) to report all effect sizes graphically. Researchers should avoid plotting point estimates without also plotting uncertainty information (using, e.g., error bars).
▸ Exemplar: simple effect size (specifically in the “Reporting simple effect size” sub-section)
A standardized effect size is a unitless measure of effect size. The most common measure of standardized effect size is Cohen’s d, where the mean difference is divided by the standard deviation of the pooled observations (Cohen 1988) \(\frac>>\) . Other approaches to standardization exist [prefer citations]. To some extent, standardized effect sizes make it possible to compare different studies in terms of how “impressive” their results are (see How do I know my effect is large enough?); however, this practice is not without criticism (see the section Standardized mean differences let us compare and summarize results when studies use different outcome scales of (Cummings 2011) ).
Standardized effect sizes are useful when effects expressed in different units need to be combined or compared (Cumming 2014) , e.g., a metaanalysis of a literature where results are reported using different units. However, even this practice is controversial, as it can rely on assumptions about the effects being measured that are difficult to verify (Cummings 2011) .
However, interpretations of standardized effect sizes should be accompanied by an argument for its applicability to the domain. If there is no inherent rationale for a particular interpretation of the practical significance of a standardized effect size, it should be accompanied by another assessment of the practical significance of the effect. Cohen’s rule of thumb for what constitutes a small, medium, or large effect size is specific to his domain and has been shown not to be generalizable. See controversial issues about effect sizes
Based on the principle of simplicity, simple effect sizes should be preferred over standardized effect sizes:
Only rarely will uncorrected standardized effect size be more useful than simple effect size. It is usually far better to report simple effect size. (Baguley 2009)
Simple effect sizes are often easier to interpret and justify (Cumming 2014; Cummings 2011) . When the units of the data are meaningful (e.g., seconds), reporting effect sizes expressed in their original units is more informative and can make it easier to judge whether the effect has a practical significance (Wilkinson 1999a; Cummings 2011) .
Reporting simple effect sizes also allow future researchers to estimate and interpret variance with Bayesian methods. Reporting the simple effect size also consistent with the principle of simplicity
Although there exist rules of thumb to help interpret standardized effect sizes, these are not universally accepted. See What about Cohen’s small, medium, and large effect sizes?
It is generally advisable to avoid the use of arbitrary thresholds when deciding on whether an effect is large enough, and instead try to think of whether the effect is of practical importance. This requires domain knowledge, and often a fair degree of subjective judgment. Ideally, a researcher should think in advance what effect size they would consider to be large enough, and plan the experiment, the hypotheses and the analyses accordingly (see the experiment and analysis planning FAQ).
Nevertheless, more often than not in HCI, it is difficult to determine whether a certain effect is of practical importance. For example, a difference in pointing time of 100 ms between two pointing techniques can be large or small depending on the application, how often it is used, its context of use, etc. In such cases, forcing artificial interpretations of practical importance can hurt transparency. In many cases, it is sufficient to present effect sizes in a clear manner and leave the judgment of practical importance to the reader.
Simple effect sizes provide the information necessary for an expert in the area to use their judgment to assess the practical impact of an effect size. For example, a difference in reaction time of 100ms is above the threshold of human perception, and therefore likely of practical impact. A difference of 100ms in receiving a chat message in an asynchronous chat application is likely less impactful, as it is small compared to the amount of time a chat message is generally expected to take. Presenting simple effect sizes in a clear way—with units—allows the expert author to argue why the effect size may or may not have practical importance and allow the expert reader to make their own judgment.
For the judgement about standardized effect sizes, see the next section.
Conventional thresholds are sometimes used for standardized effect sizes like Cohen’s d, labeling them “small”, “medium”, or “large”. These thresholds are however largely arbitrary (Cummings 2011) . They were originally proposed by Cohen based on human heights and intelligence quotients (Cohen 1977) , but Cohen, in the very text where he first introduced them, noted that these thresholds may not be directly applicable to other domains:
The terms “small”, “medium”, and “large” are relative, not only to each other, but to the area of behavioral science or even more particularly to the specific content and research method being employed in any given investigation… In the face of this relativity, there is a certain risk inherent in offering conventional operational definitions for these terms for use in power analysis in as diverse a field of inquiry as behavioral science. This risk is nevertheless accepted in the belief that more is to be gained than lost by supplying a common conventional frame of reference which is recommended for use only when no better basis for estimating the ES index is available. (Cohen 1977)
Cohen recommended the use of these thresholds only when no better frame of reference for assessing practical importance was available. However, hindsight has demonstrated that if such thresholds are offered, they will be adopted as a convenience, often without much thought to how they apply to the domain at hand (Baguley 2004; Lenth 2001) ; Lenth has called this usage “canned effect sizes” (Lenth 2001) . Once adopted, these thresholds make reports more opaque, by standardizing away units of measurement and categorizing results into arbitrary classes. Such classes can even be misleading. For example, a review of 92 experiments shows that effect sizes in software engineering are larger than Cohen’s categories (Kampenes et al. 2007) .
Like Cummings (2011) , we recommend against assessing the importance of effects by labeling them using Cohen’s thresholds.